Writing tests that fail
These slides are from my lightning talk at Rails World 2024.

Here’s the setup: we’re working on a social media app and this is the next ticket for us to pick up. We need to implement a visible_comments method on the Post class, which filters out comments that are not supposed to be visible.
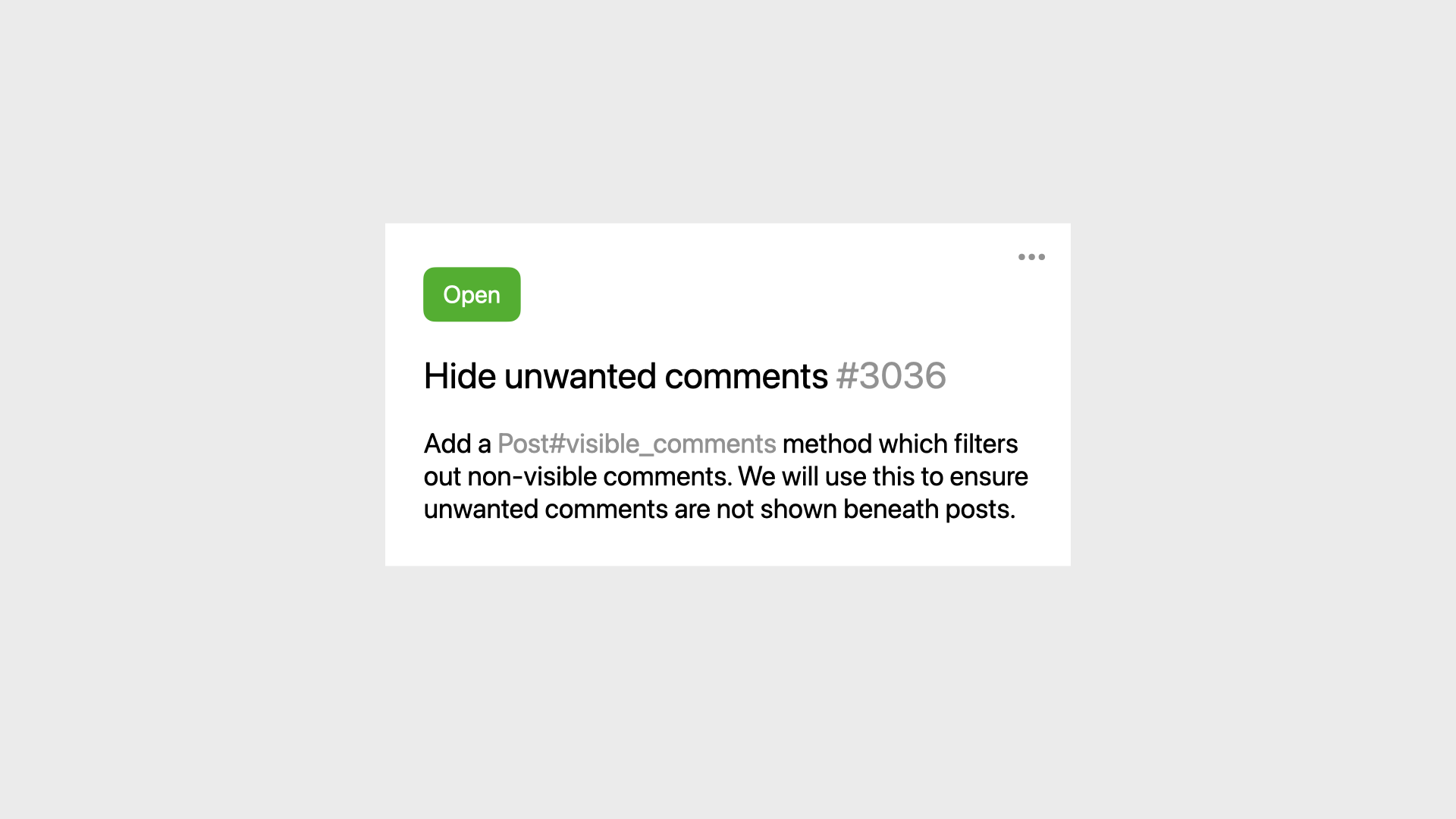
We already have a moderation mechanism that will flag these kinds of comments as hidden, we just need to filter them out so the user doesn’t see them.
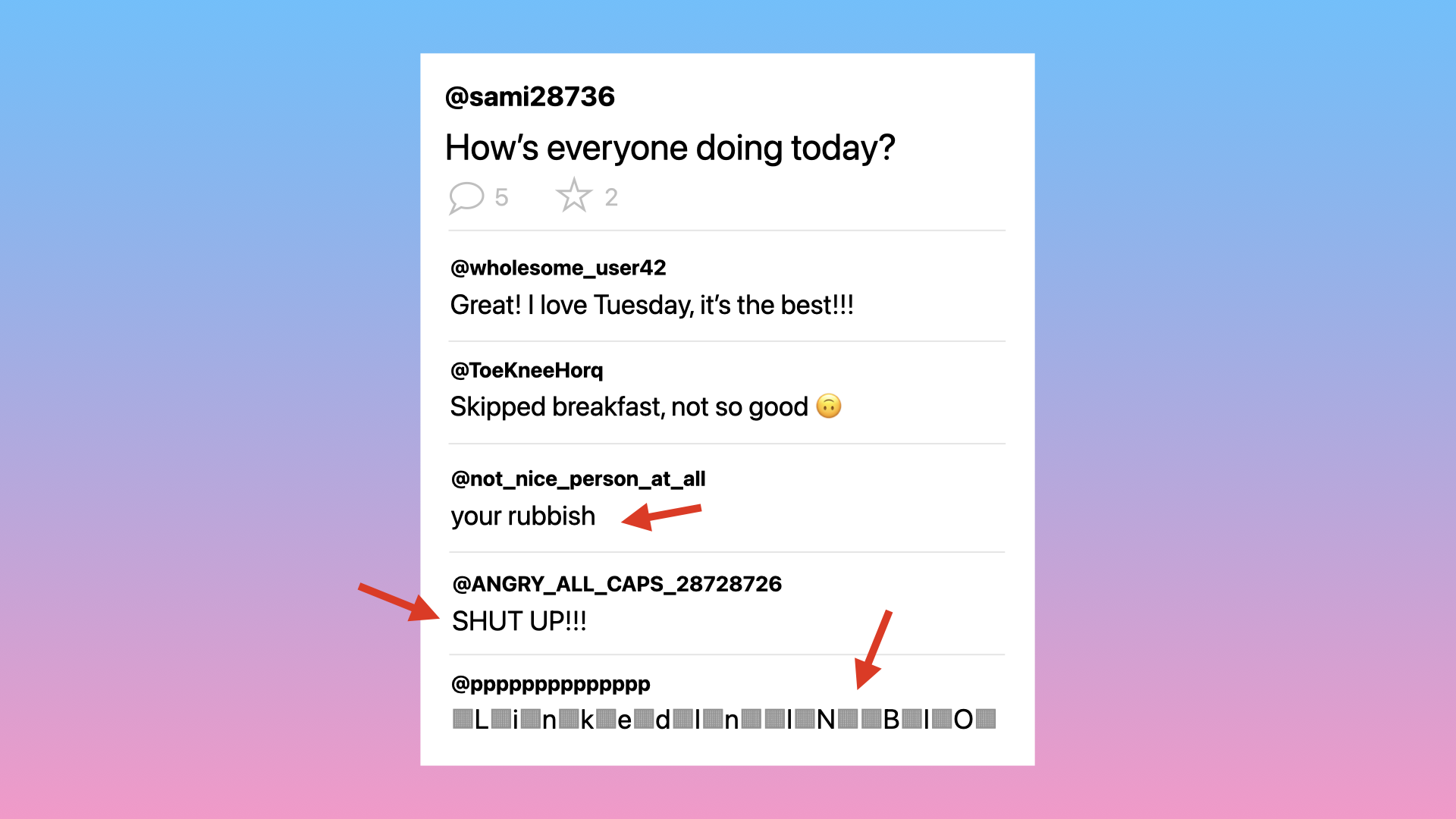
We’ll implement it by looping through each of the posts’ comments and rejecting the ones that are not visible.

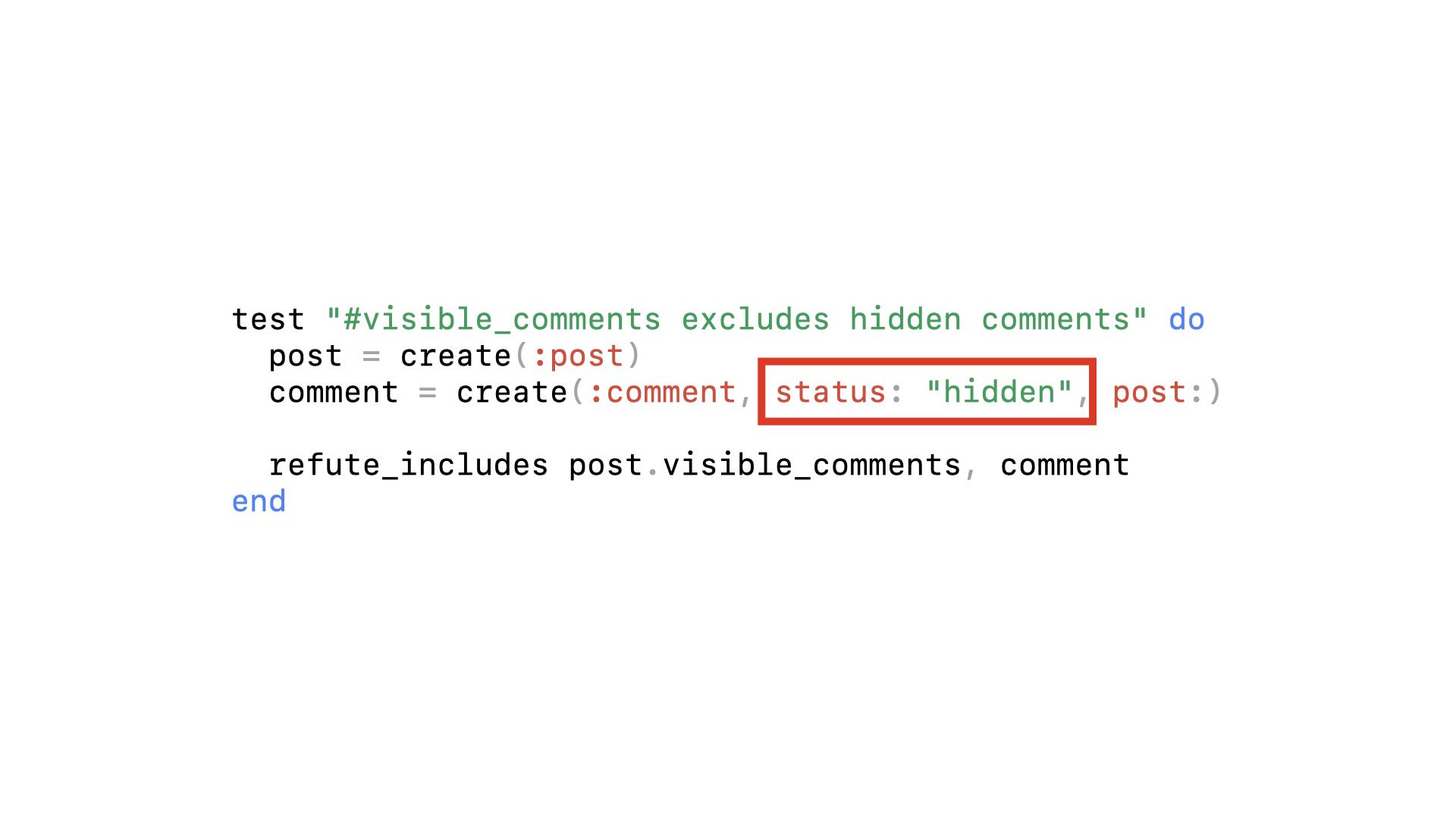
To test it, we’ll create a post and a comment with the status set to hidden. And we’ll assert that the hidden comment is not included in the visible_comments array.

We run the tests and they pass.
So we can ship it. Are we good?

We’re good. The code was correct, CI is happy, and the program is doing exactly what we want it to do in production. The user no longer sees those unwanted comments.
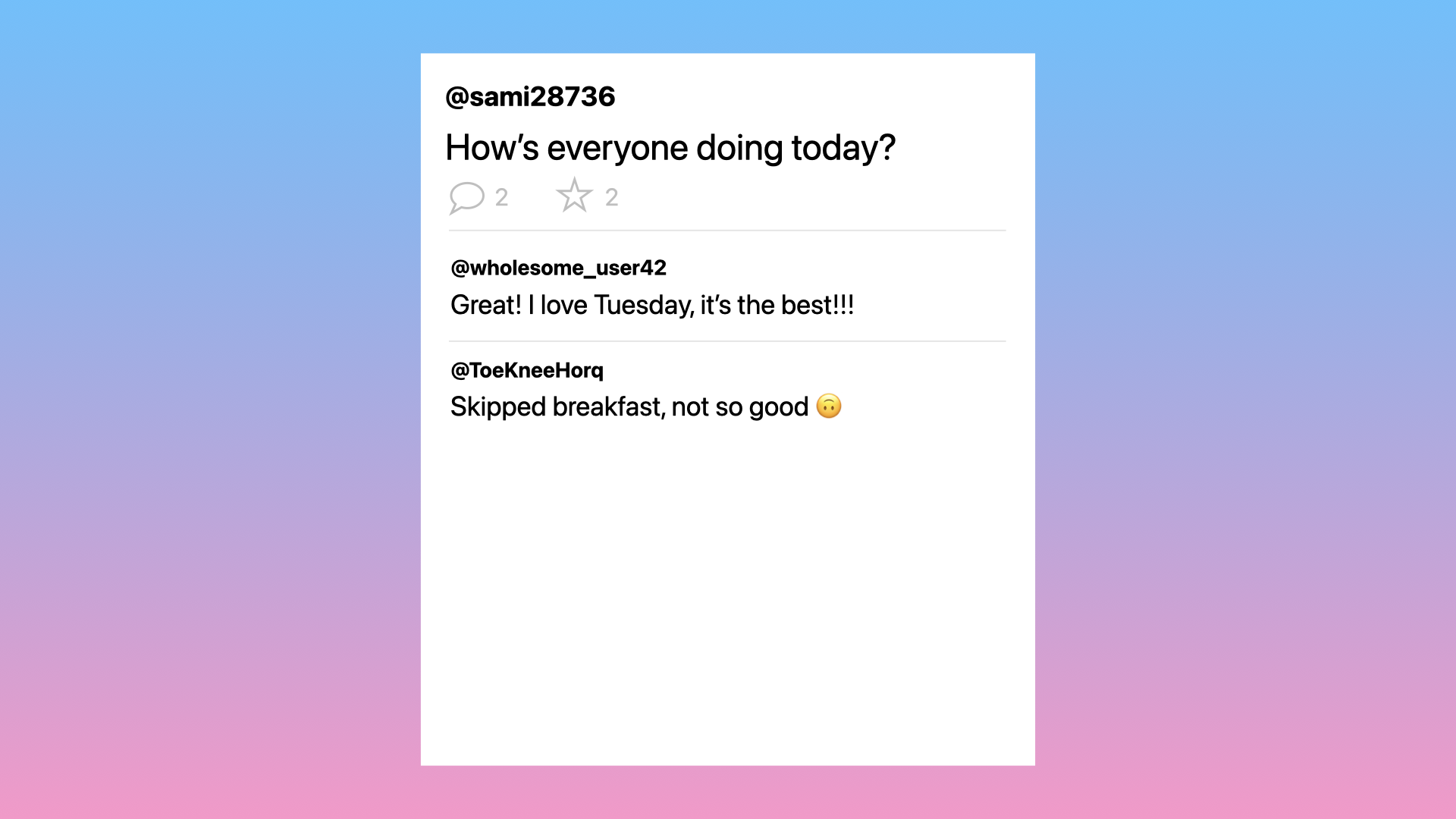
We can close the ticket and move on.
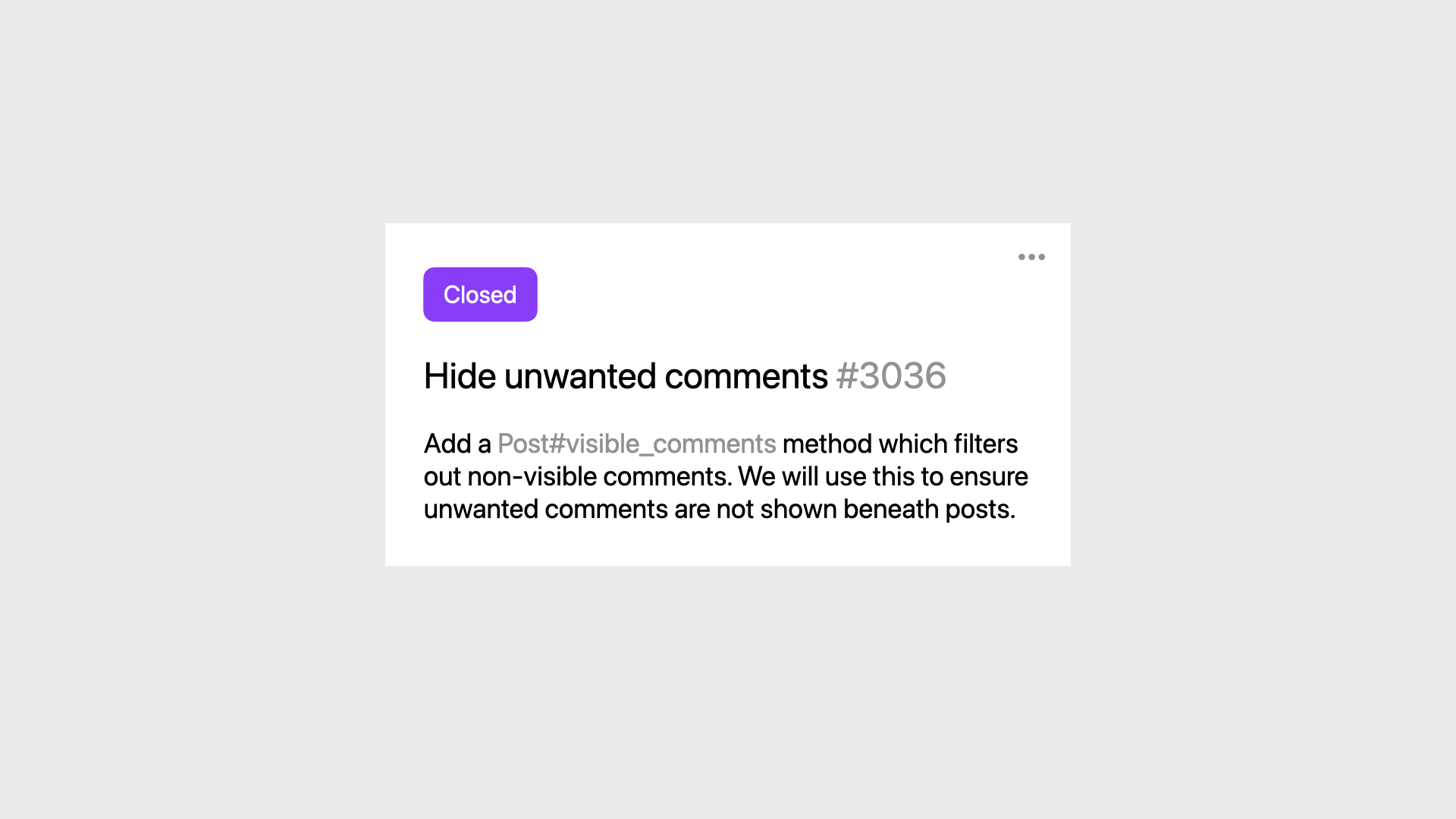
Some time later, maybe we find ourselves back in the same area of the codebase.

We decide this double-negative approach where we’re rejecting comments that are not visible is ever so slightly more difficult to reason about than it needs to be.

We can simplify it by replacing reject with select…

…and not visible with hidden.

We run the tests, they pass…
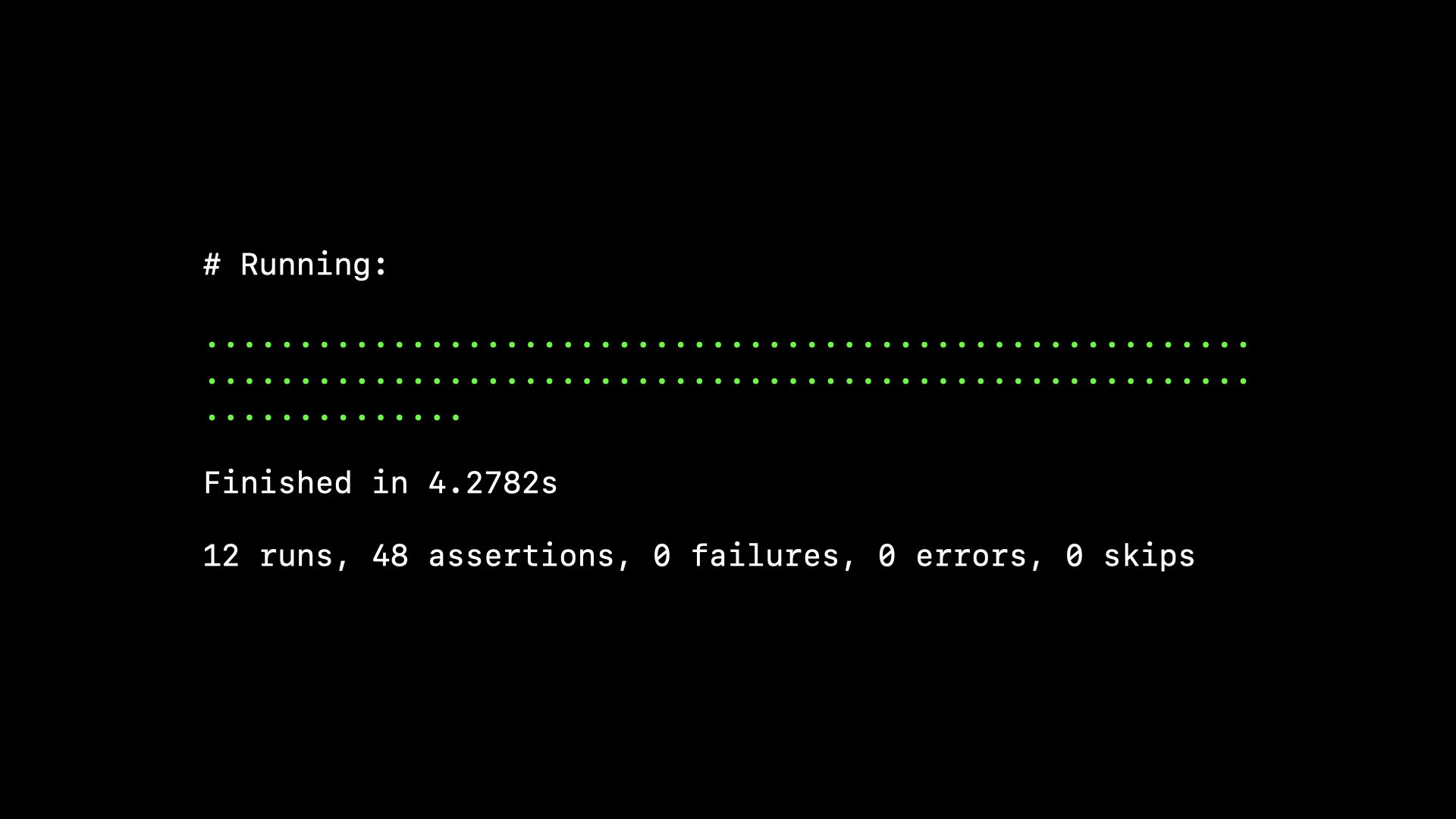
…so we can ship it. Are we good?

No, we’re not good. We obviously did have a problem reasoning about that double-negative, because our cosmetic refactor has inadvertently flipped the logic to be the exact opposite of what we wanted: we’re now only showing hidden comments.

Instead of switching not visible for hidden…

…we should have switched not visible for visible. It’s a silly mistake but an easy fix.

But our tests passed? The thing about passing tests, is that they’re not particularly useful.
Failing tests are really useful because they tell us something is wrong. Maybe our code is incorrect, or the test itself isn’t quite right. But something specific is wrong and we can fix it. Failing tests are so useful, they often point us directly to a line in our codebase where there is a problem.
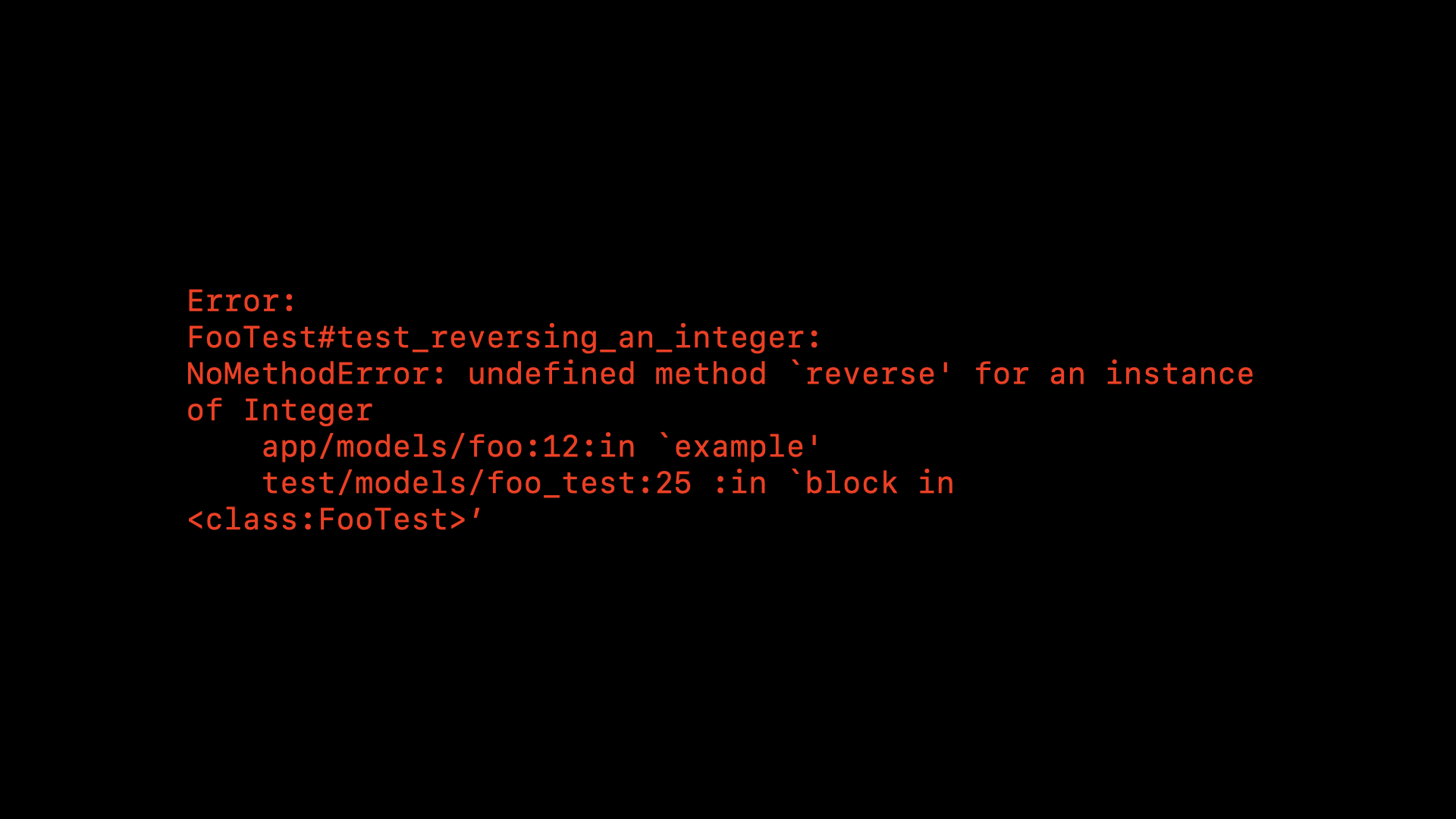
But what do passing tests tell us? They certainly don’t guarantee our code is correct. They might give us a degree of confidence that our code is probably correct, but only if the tests themselves are correct—and who’s testing the tests?
Perhaps the problem is obvious in this simplified example. In a real project it might be more subtle. The test setup might be dozens of lines split across several helper methods, and we might be modeling more complex and nuanced relationships and dependencies.
Here though it’s simple: the comment we create is completely unrelated to the post. It doesn’t matter what the status is. It doesn’t really matter what the implementation looks like. There’s no reason this comment would ever appear next to this post. The test always passes—it’s a false negative.

Again, it’s a silly mistake but an easy fix, we just need to associate the comment to the post. But how can we catch false negative tests like this before they result in us shipping a bug to production?

One way is that we need to see the test fail. If you practice Test Driven Development, there’s a natural opportunity to see the test fail, because that’s how TDD works: write a failing test, then make it pass. If you don’t practice TDD, you can simulate the same thing by deliberately breaking either the implementation or the test itself to see it fail before fixing it again.

Since we already have the now-fixed implementation and the now-fixed test, let’s do the latter approach. Let’s take a look at this test again.

This is the interesting part. This is a kind of switch that enables the behavior we’re expecting to see. If it wasn’t set (or was set to some other value or default value) then the behavior we’re making assertions about just wouldn’t materialize—something else would presumably happen instead and the test should fail.
If we bring it out into it’s own line, we can make it clearer that this is different and more important than the rest of the test setup.

This part is about setting up the default state for our test. It might be necessary in order for the test to make sense, but it’s not the specific detail we’re testing.

And this more important part modifies that default state to enable the specific behavior we’ll make assertions about later.

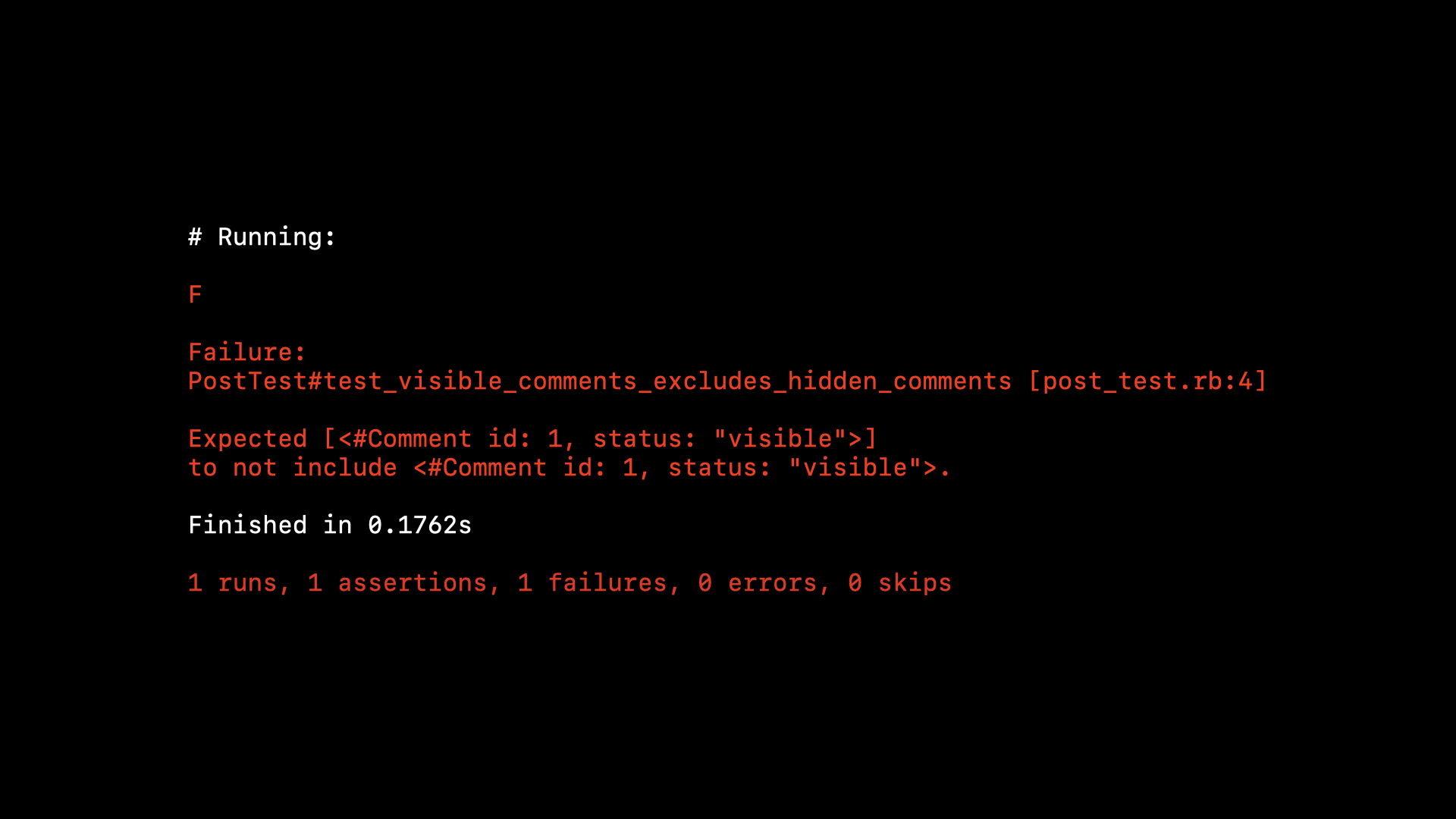
If we comment out that line and run just this test, we should see it fail…

Great. So we’ve fixed the code, fixed the test, and verified it’s no longer a false negative.
We can ship it and move on.

Some time later though, we have a new requirement.

We shouldn’t show comments at all if the post hasn’t been moderated yet.
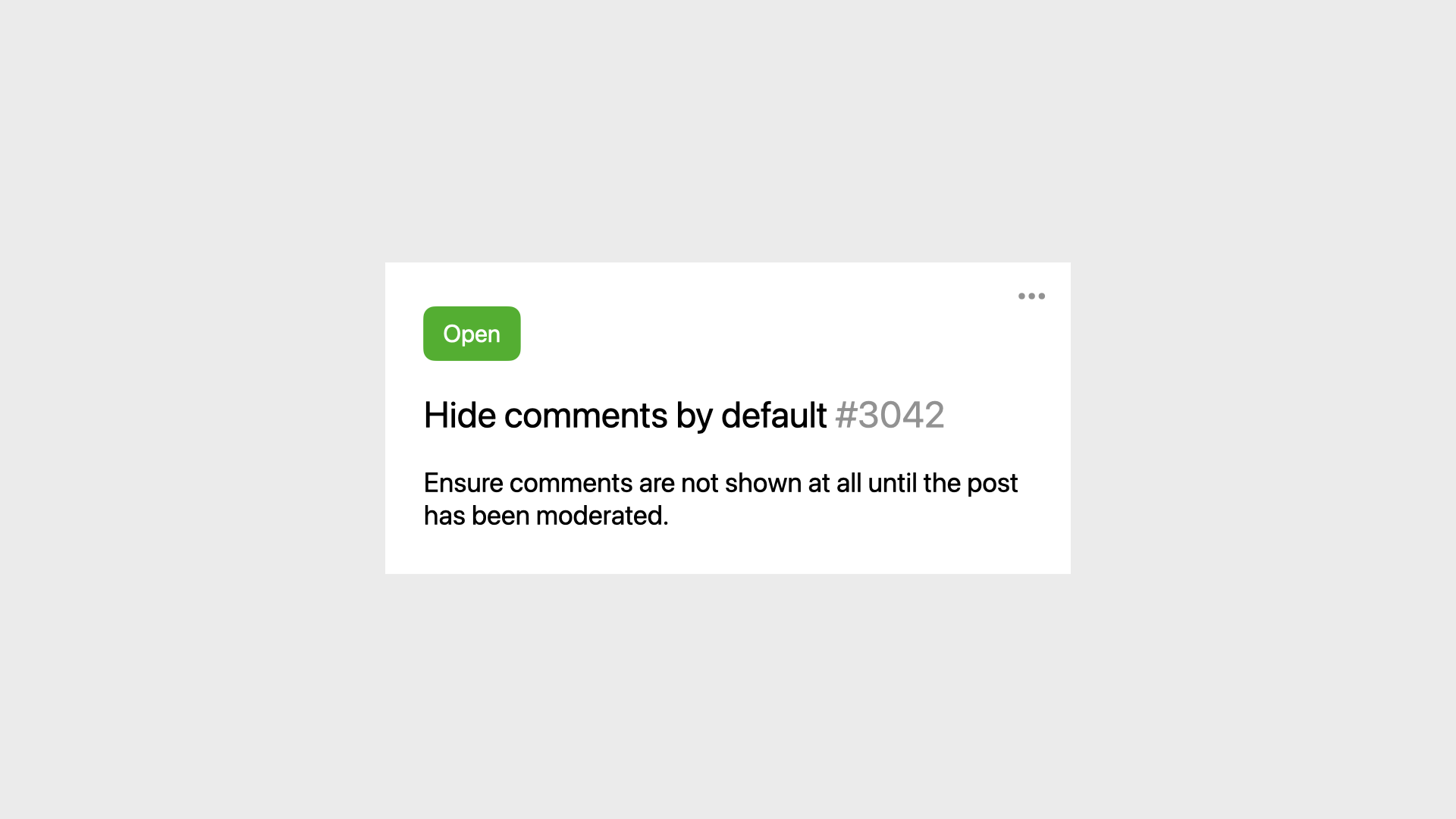
It’s a one line change, nice.

And our tests still pass, great!
Wait… hang on a second… our tests still pass despite us changing the behavior quite significantly? I thought we just verified that the test was not a false negative?

Unfortunately if we’re not careful, tests that aren’t currently false negatives can quite easily become false negatives when things change.

By adding this guard clause, we changed the default behavior of the method so our test setup no longer makes sense.

And when we make this negative assertion, it now applies equally to the default state as it does the modified state.

This line is no longer enough to enable the behavior we want.
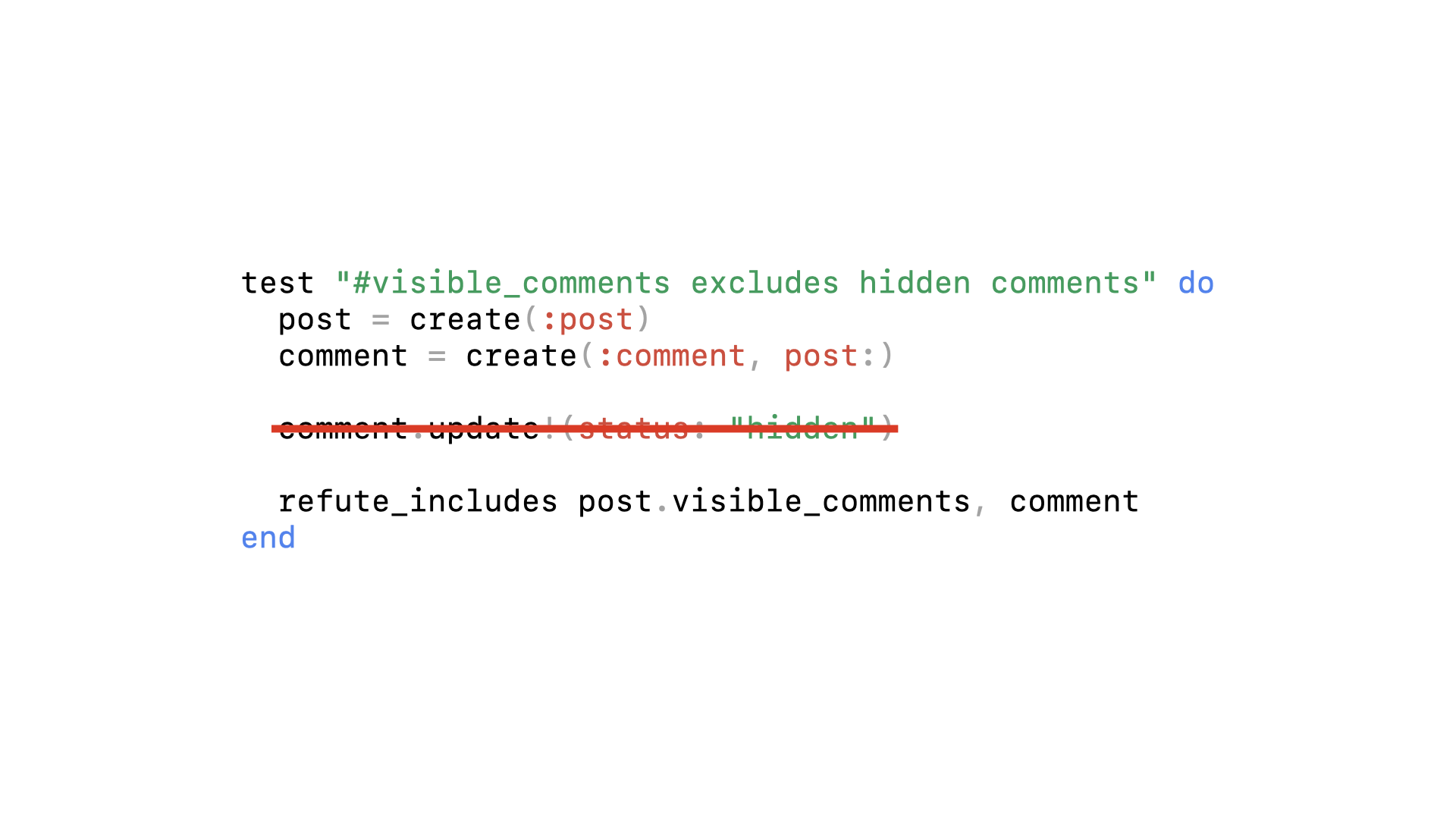
In fact we can change or break the code completely and our test still passes.

So to confirm whether or not it’s a false negative, we actually need to see the test fail again, each time we change something in our code or tests.
But we can’t continually comment this line out and in again every time we change anything, that’s clearly impractical. But computers are quite good at impractical things. How about instead of wrapping that line in a comment…

…we wrap it in a block.

When the contents of the block are evaluated, the test is running normally and should pass.

When the contents of the block are not evaluated (i.e. the computer has commented it out for us), we should expect the test to fail.

So each time we run the test twice: a normal run and a verification run. If during the verification phase there are no assertion failures (i.e. the test passed both times)…
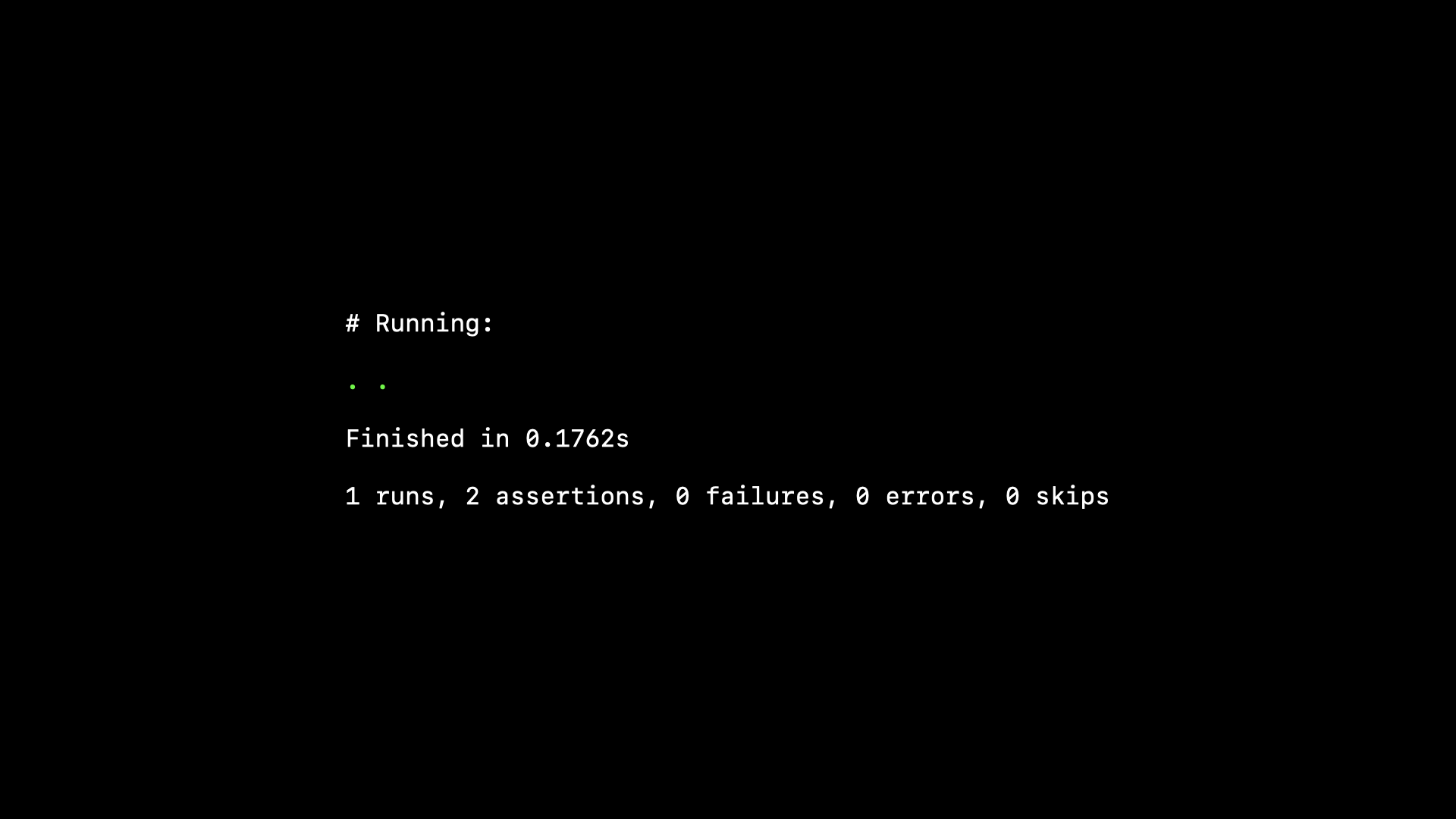
…we’ll generate our own assertion failure saying we expected our test to fail but it didn’t—it’s a false negative.
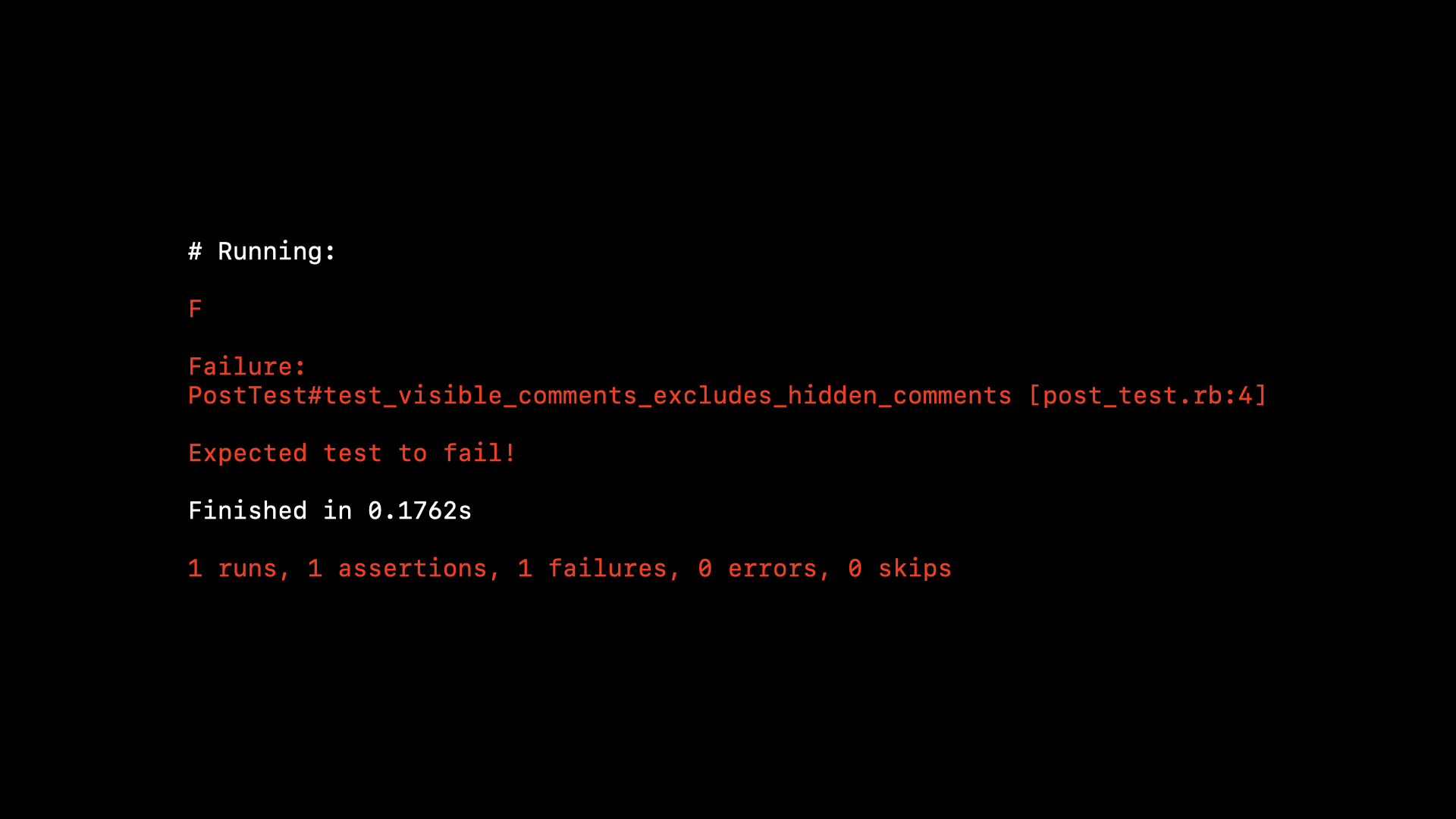
This is a proof-of-concept Minitest plugin to demonstrate this idea. It works fine, but it’s probably not practical to use in a real project. For a start, it’s going to run all of our tests twice, which is probably not a trade off many of us are willing to make. It also requires us to write our tests in a very particular and peculiar way—if we get it wrong we might think the tool is doing something useful when it’s not.

So if it’s not practical to catch false negatives programmatically, what are some more practical things we can do to avoid writing them in the first place?

We should pair negative assertions with positive ones.
Asserting that something doesn’t exist, or isn’t in a list, can be dangerous. These are perfectly valid assertions that we might want to make about our program, but they often line up with the default state of the world. Most things aren’t in most lists, so asserting that something isn’t in a list could easily pass by default.

Similarlay we should pair dynamic assertions with static ones.
In this example, if the list of comments is empty, then we aren’t actually making any assertions and the test will silently pass. We can sense check the dynamic assertions by (for example) asserting that the list isn’t empty first.

Rather than asserting how things are at the end of a test, make assertions about how things have changed since the beginning of the test. This helps verify that the final state is actually different from the default state of our test. If it’s not, then our test hasn’t done anything.

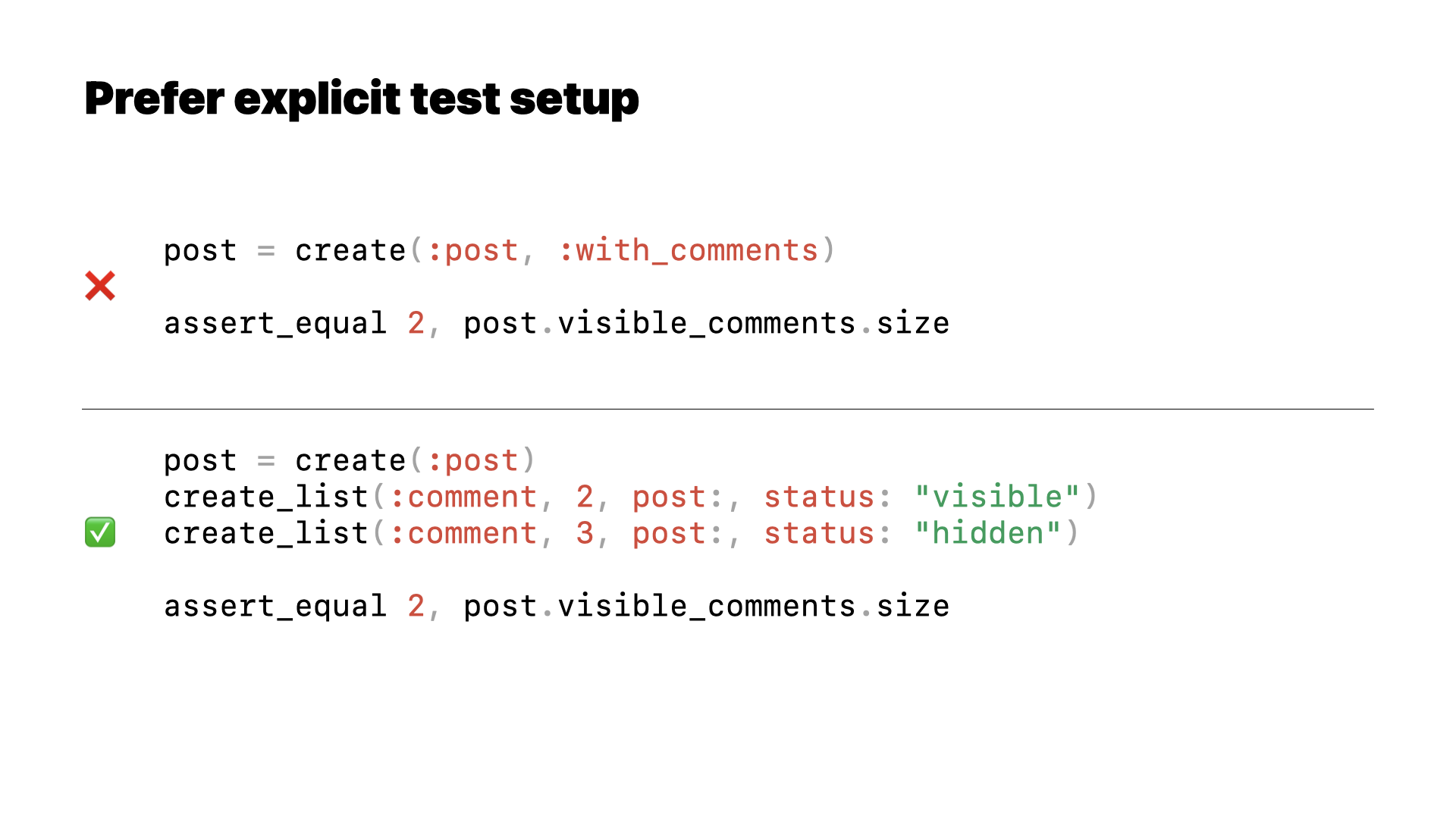
We can use more explicit test setup.
It’s tempting to make assertions about existing factories or fixtures defined elsewhere. But not only do we lose important context that explains what we think our test is doing, it’s really easy for that setup to change and our test might stop making sense.
When we manually verify our tests are not false negatives, we need to make sure the failures are meaningful. For example a NameError or NoMethodError don’t necessarily indiciate we don’t have a false negative, it might just mean we commented out the wrong thing and broke our test setup.

To summarize: it’s easy to write false negative tests by mistake. The examples here were contrived to be simple, but in a real codebase you might make a change several steps removed from a false negative test and not realize.
Tests can become false negatives over time, so even if we see them fail when we first write them, that doesn’t guarantee they will remain correct forever. We need to continually ensure our tests actually reflect the current implementation.
Catching false negative tests with tooling is probably impractical, so instead we should practice good testing habits, write robust tests, and make sure we see them fail.